- Excellent Multilingual Text Rendering: Supports high-precision text generation in multiple languages including English, Chinese, Korean, Japanese, maintaining font details and layout consistency
- Diverse Artistic Styles: From photorealistic scenes to impressionist paintings, from anime aesthetics to minimalist design, fluidly adapting to various creative prompts
Qwen-Image Native Workflow Example
VRAM usage reference Tested with RTX 4090D 24GB Model Version: Qwen-Image_fp8- VRAM: 86%
- Generation time: 94s for the first time, 71s for the second time
- VRAM: 96%
- Generation time: 295s for the first time, 131s for the second time
1. Workflow File
After updating ComfyUI, you can find the workflow file in the templates, or drag the workflow below into ComfyUI to load it.
Download JSON Workflow
2. Model Download
Available Models in ComfyUI- Qwen-Image_bf16 (40.9 GB)
- Qwen-Image_fp8 (20.4 GB)
3. Complete the Workflow Step by Step
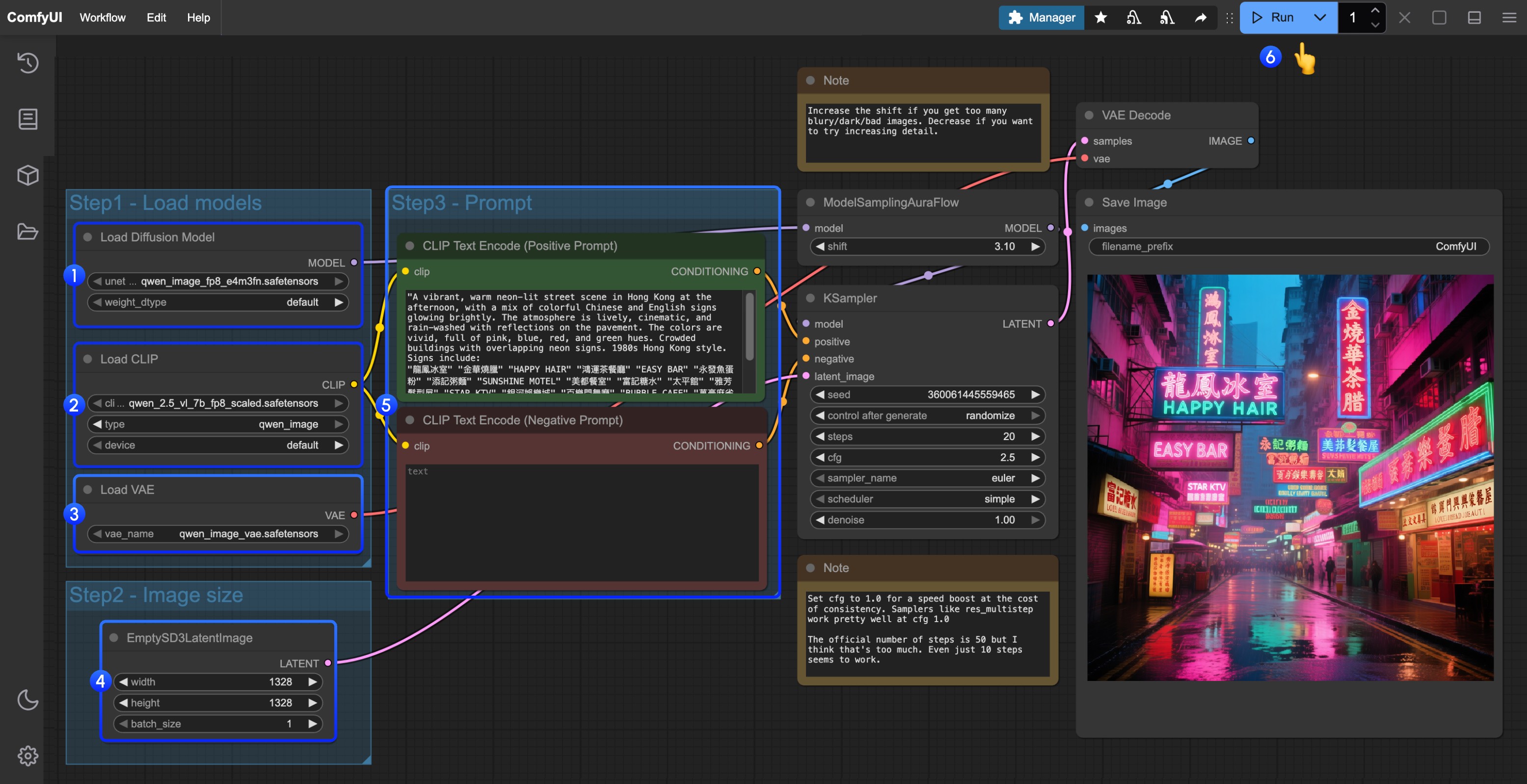
- Load
qwen_image_fp8_e4m3fn.safetensorsin theLoad Diffusion Modelnode - Load
qwen_2.5_vl_7b_fp8_scaled.safetensorsin theLoad CLIPnode - Load
qwen_image_vae.safetensorsin theLoad VAEnode - Set image dimensions in the
EmptySD3LatentImagenode - Enter your prompts in the
CLIP Text Encoder(supports English, Chinese, Korean, Japanese, Italian, etc.) - Click Queue or press
Ctrl+Enterto run